


Wouldn't it be good that you could extract your virtual server out of your current cloud provider, and import it in another provider, or import in a virtual machine manager installed locally ? That it's possible, but it depends on two conditions:
- have access to a repair environment in a recovery console in your cloud provider, allowing installs
- a remote storage system that allow uploads
Recovery console in the cloud provider
If your local desktop PC fails for any reason, usually you can fix it restarting the system in rescue mode, which allows you to grab your data and eventually correct the problem that is preventing the system to boot. Usually you do this to a special recovery partition created by your PC manufacturer or using a bootable USB drive that allows to run a pre-install environment (like WinPE or a Linux Live ISO). The local disks are mounted after this special rescue environment is booted and you can proceed to do the proceedings to fix/extract the data. In your remote virtual server, which you don't have physical access to, your provider can provide this recovery environment. One of the cloud providers I use, Digital Ocean, offers this recovery environment. Other providers, like Amazon EC2, Google Cloud Platform, and Azure offer their own recovery environments. The complexity level of the procedure also depends on your objective, if it is only to get the data or if you want to replicate the entire environment of the virtual server (configuration settings, partition metadata, virtual disks, OS services, kernel version, etc.). If you go for the data, the process is less prone to error, if you want the latter, grab a cofee and cross finger and pray for everything going well.
Imaging the storage units
You'll need a tool to clone your storage devices, bit by bit in a linear way, to a storage resource mounted locally or virtually. What matters is if the entire filesystem is corrupted, you'll have more chances of recovering your data.
A concrete example
For the purposes of this publication, I'll be using an Ubuntu 18 server hosted in the DigitalOcean cloud, created from a fresh and recent installation. The recovery environment is provided by DigitalOcean for all droplets, which is the term that DigitalOcean for its VPSs. For the storage system in which I'll be saving the VPS data, we'll use digitalOcean Spaces, which is compatible with Amazon S3.
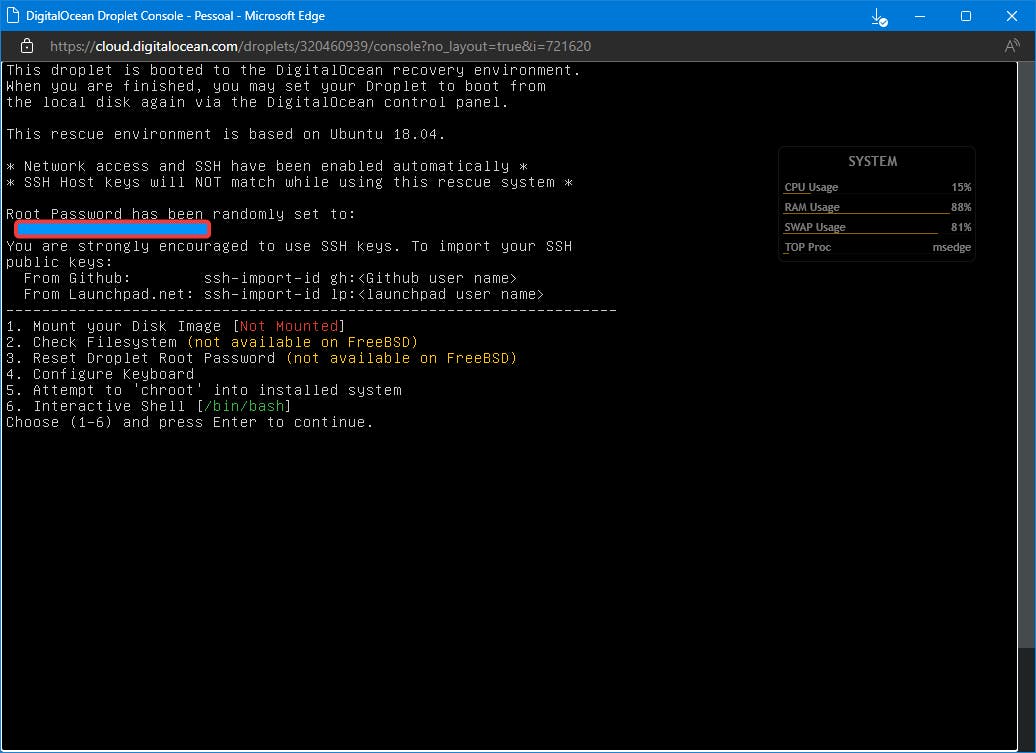
Launch the recovery environment
- In Digital Ocean dashnoard, select your droplet, in the little sidebar menu that the last option is "Recovery". Click in there:
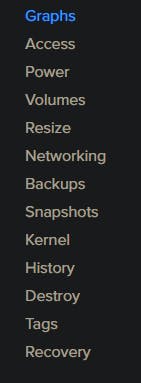
- On the two radio buttons that appear on the right, select "Boot from Recovery ISO".
- Turn off the droplet from the dashboard or from the command line
- Turn the droplet on and open the recovery console
- On the recovery console choose choose option 6 "Interactive Shell (/bin/bash)"
Install auxiliary tools
- Once the shell appears, type in the following commands:
apt install pv s3cmd
pv is the progress viewer that allows to have a progress meter inbetween shell programs that allow piping streams between them (remember, disk druid (dd) does not provide you with such a thing), s3cmd is a S3 client that we'll use for uploading to a S3 Bucket.
Let's what our droplet partition list:

Our main virtual disk vdaconsists of two partitions, vda1 amd vda3. Both are not mounted, which we wouldn't be doing, since we're cloning the big one, vda3 which holds the OS root filesystem (vda1 is the special BIOS boot partition). But for our purposes, we want to replicate the whole virtual server, so er're going to clone the entire virtual disk.
Clonin' and uploadin'
Just type the following command:
dd if=/dev/vda bs=4M conv=sparse | pv -s 25G | gzip -1 - | s3cmd put - s3://yourbucket/your-droplet-image.img.gz
Now let's hold on for a sec and explain what's in here:
ddis the disk imaging program, it reads the disk bit by bit, grouping in 4 megabytes and sending them to stdout, which we'll pipe intopv, which provides the progress bar in text mode,-s 25Gis the size of the partition, to letpvcalculate estimated time to complete the operation, an them redirects the stdout to gzip archiving program, which will compress the data (we don't want a whole 25G file to download!) and send them finally to the S3 uploader, the python executables3cmd, which will send the data to the final destination of our clone image. In my case, I'll upload to a DigitalOcean Space, which is compatible with Amazon S3. From there, I can grab the image archive through plain old HTTP. This way, we don't have to worry about mounting a third volume, which would be serving as an intermediary medium, and you would pay for their use. Spaces is also charged (at 5 bucks per month with a total limit of 250 GB of storage and 1 TB of traffic ), independently if put less or more data in it, unless you surpass the limit. Now with the disk image in your computer, unpack it and attach the image to a virtual machine manager like VirtualBox. If you are in luck, you will have a nice a local copy of your virtual server in your desktop that you can upload later to another cloud provider.